The FreeBSD Diary |
| (TM) | Providing practical examples since 1998If you buy from Amazon USA, please support us by using this link. |
|
NetSaint - creating a plug-in for RAID monitoring
11 August 2006
|
|
This article originally appeared in OnLAMP. In a previous article I talked about my RAID-5 installation. It has been up and running for a few days now. I'm pleased with the result. However, RAID can fail. When it fails, you need to take action before the next failure. Two failures close together, no matter how rare that may be, will involve a complete reinstall1. I have been using NetSaint since first writing about it back in 2001. You will notice that NetSaint development has been continued under a new name - Nagios. For me, I continue to use NetSaint. It does what I need. The monitoring consists of three main components:
With these simple tools, you'll be able to monitor your RAID array. 1For my setup at least. I'm sure that you might know of RAID setups that allow for multiple failures, but mine does not. |
|
Monitoring the array
|
|
Monitoring the health of your RAID array is vital to the health of your system. Fortunately, Adaptec has a tool for this. It is available within the FreeBSD sysutils/asr-utils port. After installing the port, it took me a while to figure out what to use and how to use it. The problem was compounded by a run-time error which took me down a little tangent before I could get it running. I will show you how to integrate this utility into your NetSaint configuration. My first few attempts at running the monitoring tool failed with this result: # /usr/local/sbin/raidutil -L all
After some Googling, I found
this reference. The problem
was shared memory. It seems that with PostgreSQL running, # grep SHM /usr/src/sys/i386/conf/LINT options SYSVSHM # include support for shared memory options SHMMAXPGS=1025 # max amount of shared memory pages (4k on i386) options SHMALL=1025 # max number of shared memory pages system wide options SHMMAX="(SHMMAXPGS*PAGE_SIZE+1)" options SHMMIN=2 # min shared memory segment size (bytes) options SHMMNI=33 # max number of shared memory identifiers options SHMSEG=9 # max shared memory segments per process These kernel options are also available as sysctl values: $ sysctl -a | grep shm kern.ipc.shmmax: 33554432 kern.ipc.shmmin: 1 kern.ipc.shmmni: 192 kern.ipc.shmseg: 128 kern.ipc.shmall: 8192 kern.ipc.shm_use_phys: 0 kern.ipc.shm_allow_removed: 0
I stared playing with kill -HUP `cat /usr/local/pgsql/data/postmaster.pid`
Now that The output shows:
It is a subset of this information which we will use to determine whether or
not all is well with the RAID array. Our next task will be experimentation
to determine what
Note: |
|
Know your RAID
|
|
I'm sure that each RAID utility will have different responses to different
situation. I am about to investigate what
Normal
Here is what # /usr/local/bin/raidutil -L logical Address Type Manufacturer/Model Capacity Status --------------------------------------------------------------------------- d0b0t0d0 RAID 5 (Redundant ADAPTEC RAID-5 228957MB Optimal Degraded
I shutdown the system, removed the power from one drive, then rebooted.
Here is what # /usr/local/bin/raidutil -L logical Address Type Manufacturer/Model Capacity Status --------------------------------------------------------------------------- d0b0t0d0 RAID 5 (Redundant ADAPTE RAID-5 228957MB Degraded This is the normal situation when a disk has died, or in this case, been removed from the array.
After I add the disk back in, ReconstructionYou can also useraidutil to start the rebuilding process. This will sync up
the degraded drive with the rest of the array. This can be a lengthy process,
but it is vital.
The rebuilding can be started with this command: /usr/local/bin/raidutil -a rebuild d0 d0b0t0d0
Where
After rebuilding has started, this is what # /usr/local/bin/raidutil -L logical Address Type Manufacturer/Model Capacity Status --------------------------------------------------------------------------- d0b0t0d0 RAID 5 (Redundant ADAPTE RAID-5 228957MB Reconstruct 0% The percentage will slowly creep up until all disks are resynced. |
|
Using netsaint_statd
|
|
The scripts supplied with
netsaint_statd. It should be installed on every machine you wish
to monitor. I downloaded the
netsaint_statd
tarball and untar'd it to the directory
/usr/local/libexec/netsaint/netsaint_statd on my
RAID machine. Strictly speaking, the check_*.pl scripts do not need to be on the RAID
machine, only the netsaint_statd. You can remove them if you want. I have them
only on the NetSaint machine.
I use the following script to start it up at boot time: # /usr/local/etc/rc.d/netsaint_statd.sh start
The RAID machine now has the
This post
by RevDigger is the basis for what I did to set up
I installed the
Now that NetSaint has the tools, you need to tell it about them. I added this
to the end of my # netsaint_statd remote commands
Here are the entries I added to
service[polo]=LOAD;0;24x7;3;2;1;freebsd-admins;120;24x7;1;1;1;;check_rload! 3 service[polo]=PROCS;0;24x7;3;2;1;freebsd-admins;120;24x7;1;1;1;;check_rprocs! service[polo]=USERS;0;24x7;3;2;1;freebsd-admins;120;24x7;1;1;1;;check_rusers! 4 service[polo]=DISKSALL;0;24x7;3;2;1;freebsd-admins;120;24x7;1;1;1;;check_rall_disks Then I restarted Netsaint: After the restart, the I started to see those services in my NetSaint website. This is great!/usr/local/etc/rc.d/netsaint.sh restart |
|
RAID Notification overview
|
|
To get NetSaint to monitor my RAID array was not as simple as getting NetSaint
to monitor a regular disk. I was already using
netsaint_statd to
monitor remote machines. I have them all set up so I can see load, process count,
users, and diskspace usage. I will extend This additional feature will involved several distinct steps:
RAID Perl script
As the basis for the perl script, I used check_users.pl as supplied with
If you look at this script, you'll see that we're looking for the 3 major status values: I have decided that Degraded and unknown results will be CRITICAL, Optimal will be OK, and that Reconstruction will be a WARNING.
The next step is to modify netsaint_statd patch
The patch for Now that you have modified the daemon, you need to kill it and restart it:cd /usr/local/libexec/netsaint/netsaint_statd patch < path.to.patch.you.downloaded Add RAID to the services monitored by NetSaintNow we have the remote RAID box ready to tell us all about the RAID status. Now it's time to test it. # cd /usr/local/libexec/netsaint/netsaint_statd # perl check_adptraid.pl polo Reconstruct 85% That looks right to me! Now I'll show you what I added to NetSaint to use this new tool.
First, I'll add the service definition to
service[polo]=RAID;0;24x7;3;2;1;raid-admins;120;24x7;1;1;1;;check_adptraid.pl I have set up a new notification_group (raid-admins) because I want to be notified via text message to my cellphone when the RAID array has a problem. The contact group I created was: contactgroup[raid-admins]=RAID Administrators;danphone,dan In this case, I want contacts danphone and dan to be notified. Here are the contacts which relate to the above contact group (the lines below may be wrapped, but in NetSaint there should only be two lines): contact[dan]=Dan Langille;24x7;24x7;1;1;0;1;1;0;notify-by-email;host-notify-by-email;dan; contact[danphone]=Dan Langille;24x7;24x7;1;1;0;1;1;0;notify-xtrashort;notify-xtrashort;dan;6135551212@pcs.example.com; This shows that I will be emailed and an email will be sent to my cellphone. After restarting NetSaint, I was able to see this on my webpage: 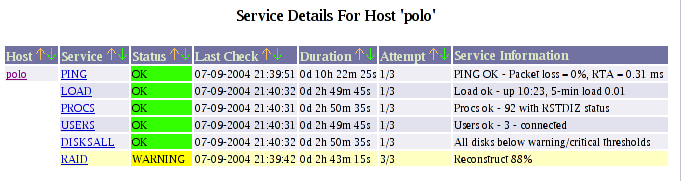
If your RAID is really important to you, then you will definitely want to test the notification via cellphone. I did. I know it works. But I hope it never has to be used. |
|
Got monitor?
|
|
I've said it before, and you're going to hear it again. RAID must be monitored if you are to achieve the full benefits of it. By using NetSaint and the above scripts, you should get plenty of time to replace a dead drive before the array is destroyed. That notification alone could save you several hours. Happy RAIDing. |